library(tidyverse)Opinion articles in The Chronicle
Suggested answers
Application exercise
Answers
Part 1 - Data scraping
See chronicle-scrape.R for suggested scraping code.
Part 2 - Data analysis
Let’s start by loading the packages we will need:
- Your turn (1 minute): Load the data you saved into the
datafolder and name itchronicle.
chronicle <- read_csv("data/chronicle.csv")- Your turn (3 minutes): Who are the most prolific authors of the 100 most recent opinion articles in The Chronicle?
chronicle |>
count(author, sort = TRUE)# A tibble: 67 × 2
author n
<chr> <int>
1 Advikaa Anand 3
2 Anthony Salgado 3
3 Billy Cao 3
4 Community Editorial Board 3
5 Heidi Smith 3
6 Linda Cao 3
7 Luke A. Powery 3
8 Monday Monday 3
9 Sonia Green 3
10 Valerie Tan 3
# … with 57 more rows- Demo: Draw a line plot of the number of opinion articles published per day in The Chronicle.
chronicle |>
count(date) |>
ggplot(aes(x = date, y = n, group = 1)) +
geom_line()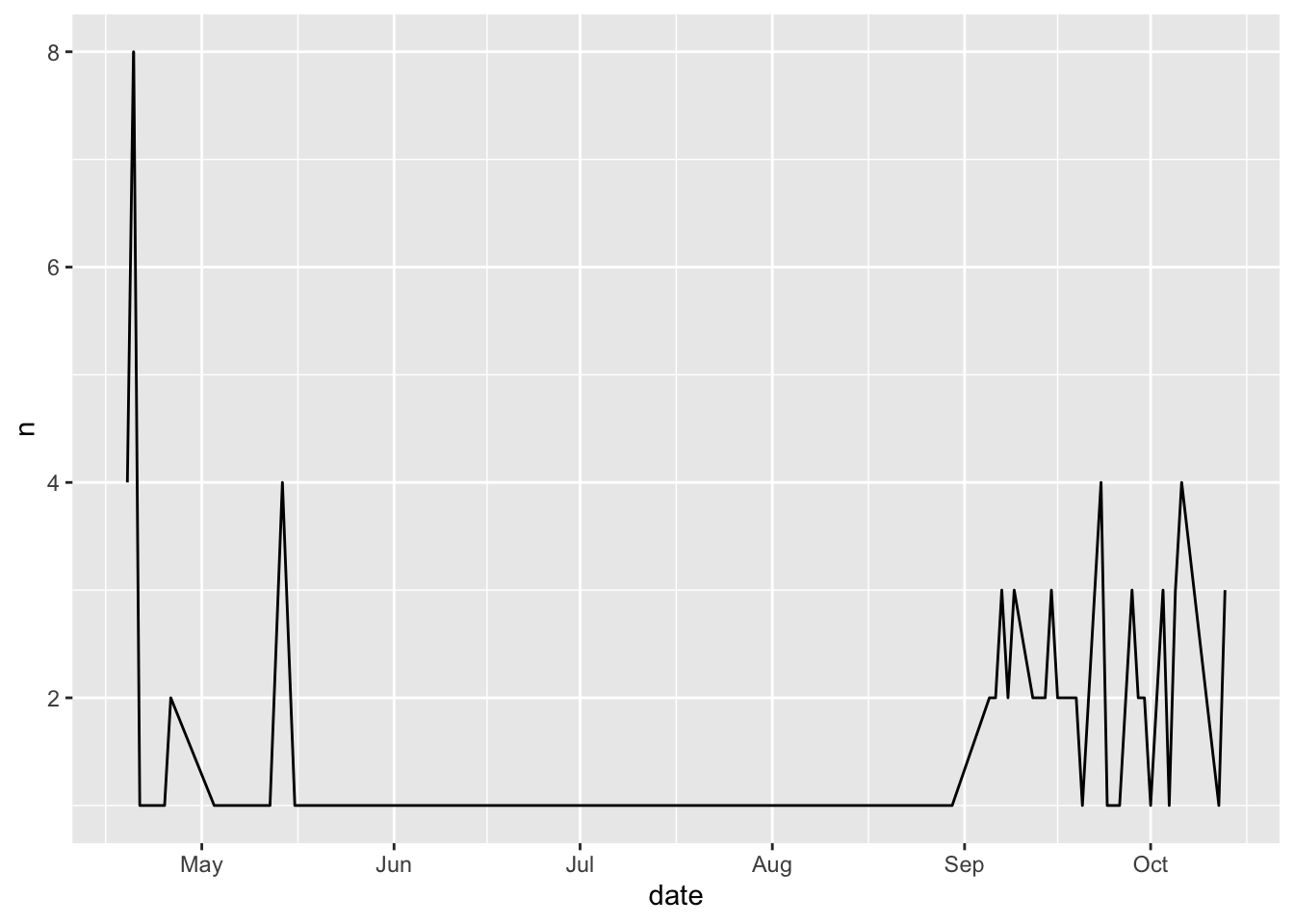
- Demo: What percent of the most recent 100 opinion articles in The Chronicle mention “climate” in their title?
chronicle |>
mutate(
title = str_to_lower(title),
climate = if_else(str_detect(title, "climate"), "mentioned", "not mentioned")
) |>
count(climate) |>
mutate(prop = n / sum(n))# A tibble: 2 × 3
climate n prop
<chr> <int> <dbl>
1 mentioned 3 0.03
2 not mentioned 97 0.97- Your turn (5 minutes): What percent of the most recent 100 opinion articles in The Chronicle mention “climate” in their title or abstract?
chronicle |>
mutate(
title = str_to_lower(title),
abstract = str_to_lower(abstract),
climate = if_else(
str_detect(title, "climate") | str_detect(abstract, "climate"),
"mentioned",
"not mentioned"
)
) |>
count(climate) |>
mutate(prop = n / sum(n))# A tibble: 2 × 3
climate n prop
<chr> <int> <dbl>
1 mentioned 4 0.04
2 not mentioned 96 0.96- Time permitting: Come up with another question and try to answer it using the data.
# add code here