# A tibble: 8 × 3
species sex n
<fct> <fct> <int>
1 Adelie female 73
2 Adelie male 73
3 Adelie <NA> 6
4 Chinstrap female 34
5 Chinstrap male 34
6 Gentoo female 58
7 Gentoo male 61
8 Gentoo <NA> 5Models with multiple predictors
Lecture 19
Dr. Mine Çetinkaya-Rundel
Duke University
STA 199 - Fall 2022
11/3/22
Warm up
While you wait for class to begin…
- Clone your
ae-18project from GitHub, render your document, update your name, and commit and push. - Post any questions you have about the material so far at sli.do / #sta199.
Announcements
- Team evaluations open – due Sat night, 11:59pm (so we can review before Monday’s lab)
- HW 5 will be posted soon
- HW 6
Questions from last time
Q: What is a two-way table?
A: A table of frequencies for two categorical variables.
How do we go from what’s on the left to what’s on the right?
# A tibble: 3 × 4
species female male `NA`
<fct> <int> <int> <int>
1 Adelie 73 73 6
2 Chinstrap 34 34 NA
3 Gentoo 58 61 5Questions from last time
Q: How do we build a two-way table in a pipeline?
Questions from last time
Q: How do we know whether we can scrape data from a website?
Questions from last time
Q: What is the proper notation for writing out a model?
- Population models (truth):
\[ y = \beta_0 + \beta_1 \times x + \epsilon \]
- Sample models (estimated):
\[ \hat{y} = b_0 + b_1 \times x \]
Goals
Fit and interpret models for predicting binary outcomes
Introduce over fitting and mitigating it by splitting the data into training and testing sets
Logistic regression
What is logistic regression?
Similar to linear regression…. but
Modeling tool when our response is categorical
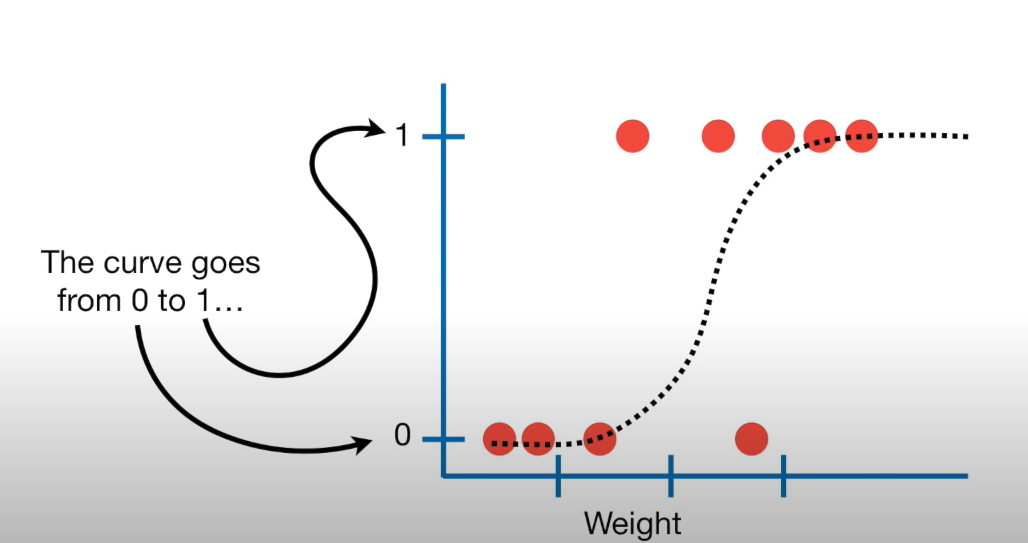
Modelling binary outcomes
Variables with binary outcomes follow the Bernouilli distribution:
\(y_i \sim Bern(p)\)
\(p\): Probability of success
\(1-p\): Probability of failure
We can’t model \(y\) directly, so instead we model \(p\)
Linear model
\[ p_i = \beta_o + \beta_1 \times X_1 + \cdots + \epsilon \]
But remember that \(p\) must be between 0 and 1
We need a link function that transforms the linear model to have an appropriate range
Logit link function
The logit function take values between 0 and 1 (probabilities) and maps them to values in the range negative infinity to positive infinity:
\[ logit(p) = log \bigg( \frac{p}{1 - p} \bigg) \]
This isn’t exactly what we need though…..
Recall, the goal is to take values between -\(\infty\) and \(\infty\) and map them to probabilities.
We need the opposite of the link function… or the inverse
Taking the inverse of the logit function will map arbitrary real values back to the range [0, 1]
Generalized linear model
- We model the logit (log-odds) of \(p\) :
\[ logit(p) = log \bigg( \frac{p}{1 - p} \bigg) = \beta_o + \beta_1 \times X1_i + \cdots + \epsilon \]
- Then take the inverse to obtain the predicted \(p\):
\[ p_i = \frac{e^{\beta_o + \beta_1 \times X1_i + \cdots + \epsilon}}{1 + e^{\beta_o + \beta_1 \times X1_i + \cdots + \epsilon}} \]
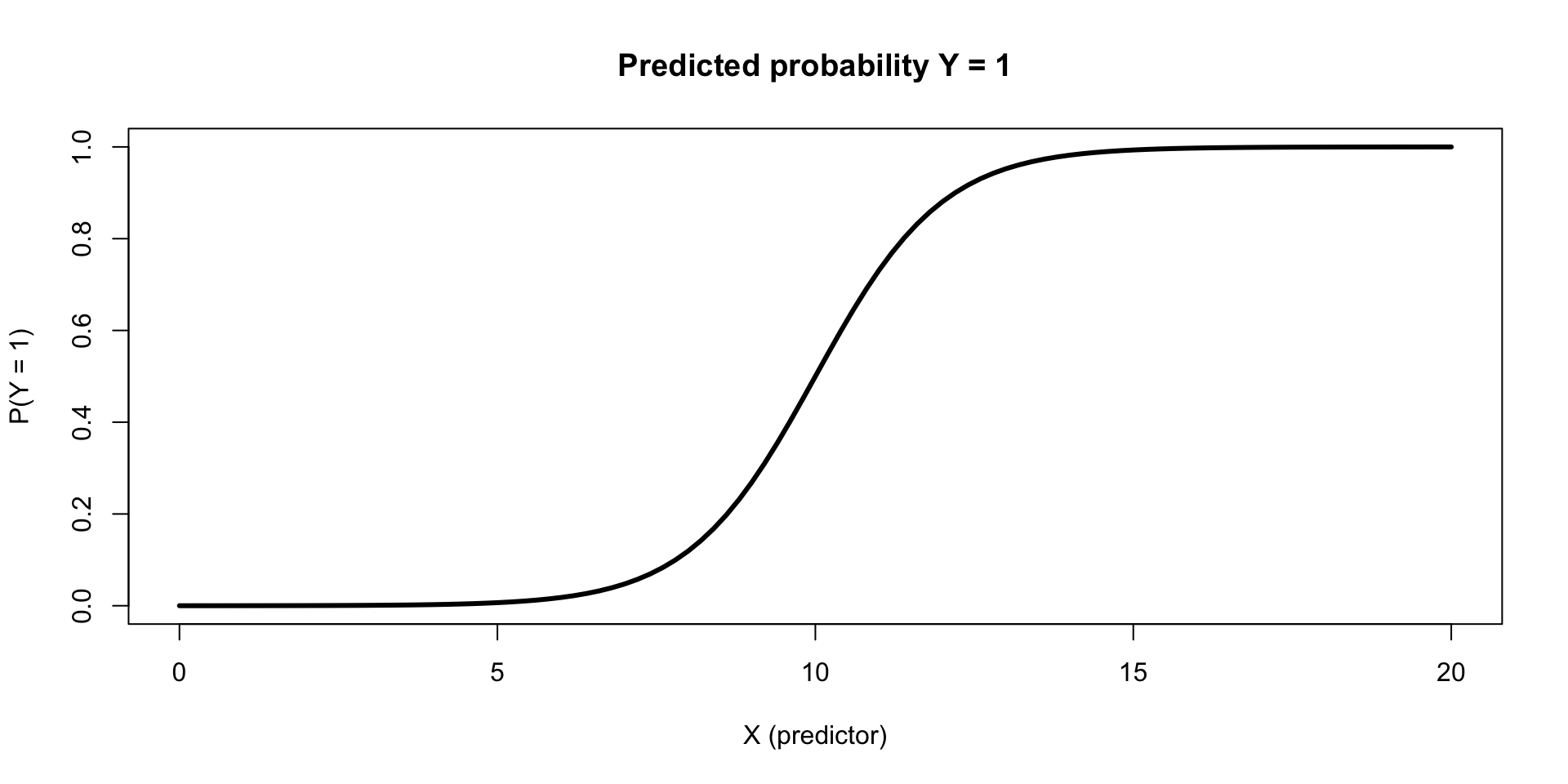
A logistic model visualized
Takeaways
Generalized linear models allow us to fit models to predict non-continuous outcomes
Predicting binary outcomes requires modeling the log-odds of success, where p = probability of success
Review questions
What is a training data set?
“Sandbox” for model building. Build the model on these data.
What is a testing data set?
Held in reserve to test one or two chosen models and to evaluate their performance.
![]()